Guide : comment faire tourner DeepSeek-R1 en local sur son Windows
Le modèle de langage de Deepseek a fasciné le monde entier en ce début d’année 2025. Mais il y a un gros inconvénient à utiliser cette IA : la sécurité des données 🔐. Elle peut exposer vos données en Chine si vous l’utilisez via leur site.
Rassurez-vous, il existe un moyen de le faire tourner localement, même sur Windows sans carte graphique dédiée !
En suivant ce guide, vous pourrez même utiliser d’autres modèles comme Mistral, Llama (Meta) ou Gemma (Google) uniquement sur votre ordinateur.
Si vous êtes perdus en cours de route, la section « Bonus » propose des solutions plus simples (c’est cadeau 🎁).
1. Utiliser Ollama pour rapidement tester le modèle
Il existe différents programmes qui permettent d’utiliser des modèles de langages en local. Mais je vous partage celui qui est le plus populaire et le plus avancé : Ollama.
Importance de la configuration de votre ordinateur
Les modèles de langages ou LLMs (Large Language Models) fonctionnent habituellement sur des énormes serveurs avec des cartes graphiques très puissantes. Evidemment ce ne sera pas le cas pour la plupart d’entre vous, donc les résultats seront moins bien si vous tournez en local.
Mais avec une configuration minimale, il est tout de même possible de faire fonctionner des modèles de langage sur votre ordinateur. Voici les 3 éléments importants qui impacteront vos performances :
La RAM : Il est préconisé d’avoir au minimum 16Gb de RAM. Mais ça devrait passer avec 8Gb (ce qui est la configuration de beaucoup d’ordinateurs portables pour la bureautique).
La carte graphique : Il est conseillé d’avoir un ordinateur avec une carte graphique dédiée. La plupart des gens ont cependant des « ultraportables » 💻, c’est-à-dire des ordinateurs fins et légers principalement pour faire de la bureautique. Dans ce cas, ce sera avec votre processeur que tournera les modèles de langages.
Le processeur : Ce n’est pas la meilleure configuration, mais les LLMs peuvent fonctionner uniquement sur votre processeur. Le modèle sera juste plus lent à vous répondre 🛺.
Je ne vais pas rentrer dans les détails pour les types de processeurs et de cartes graphiques puisqu’il en existe plusieurs centaines de versions différentes. Mais dîtes-vous tout simplement que plus les chiffres des composants sont élevés, mieux c’est (ex : un Intel i7 est mieux que l’i5…etc).
PS : Les modèles de langages prennent beaucoup de place dans votre disque dur. Veillez à avoir au minimum 10 Go de disponible pour tester un modèle 💽.
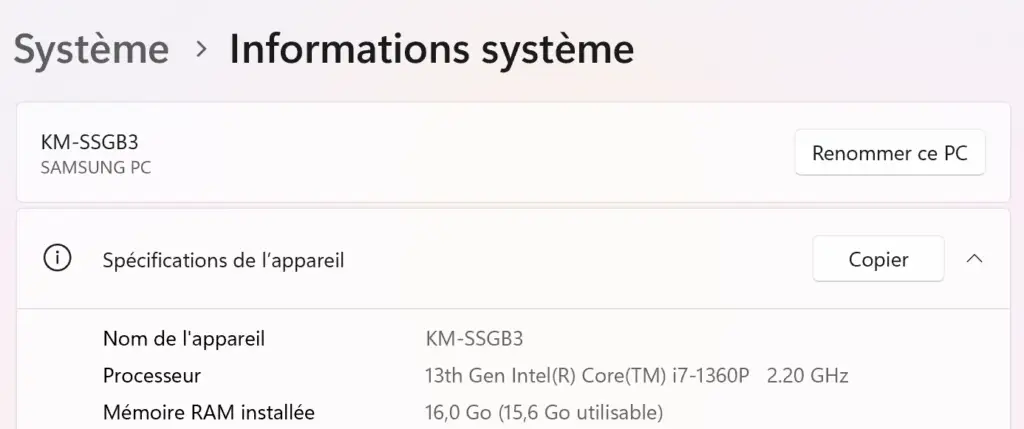
Mais comment vérifier la configuration de son ordinateur ? Il vous suffit d’aller dans vos Paramètres, puis « Système » puis « Informations système ».
Je vous donne la configuration de mon ordinateur portable pour exemple :
(Screenshot pour les informations système de mon appareil. J’ai 16GB de RAM, pas de carte graphique dédiée, un processeur Intel i7 de 13ème génération).
Installer Ollama sur son ordinateur
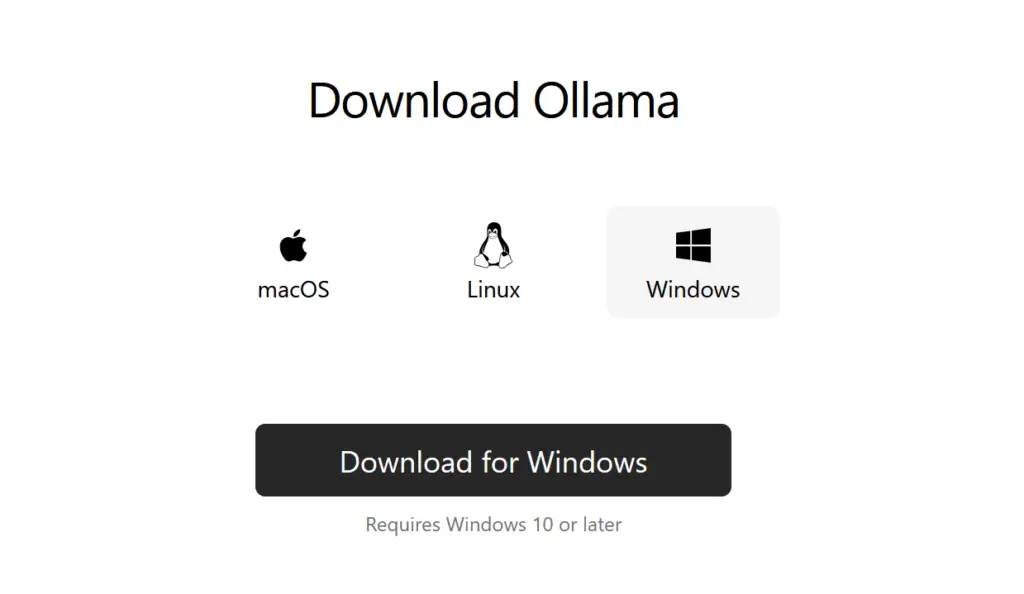
Il suffit d’aller sur leur site et cliquer sur « Download ». Le site vous demandera de choisir votre système d’exploitation. Choisissez Windows pour ce cas-ci. Si vous avez un Mac, tâchez de bien adapter chaque étape à ce système d’exploitation.
(Arrivé sur cette page, il faudra bien sélectionner « Windows »).
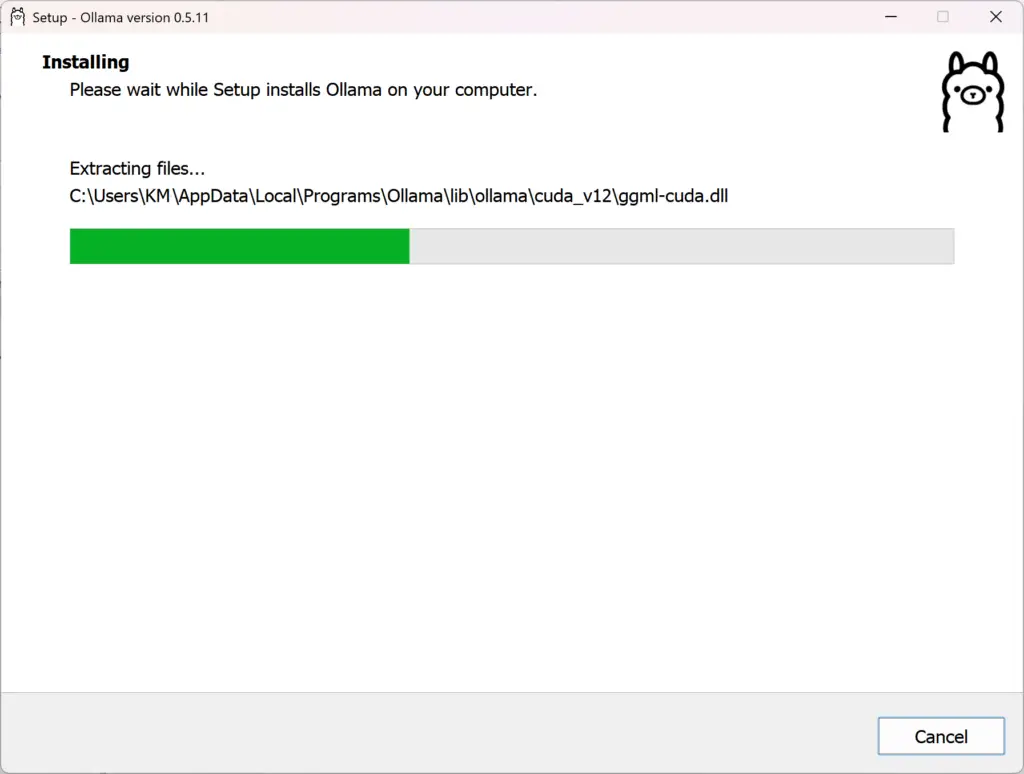
Après avoir téléchargé le fichier d’installation, il vous suffit de l’exécuter et de suivre le processus d’installation.
(Screenshot du processus d’installation d’Ollama).
À la fin de l’installation, la fenêtre se ferme et plus rien ne se passe. Vous allez peut-être vous demander si c’est un bug mais pas de panique, c’est tout à fait normal. Ollama est en train de tourner en fond, vous devez le voir apparaître dans votre barre de tâche.
(Si vous voyez un petit lama blanc parmi les programmes qui sont minimisés, c’est bon ✅)
Utiliser Ollama pour prompter
Maintenant qu’Ollama a été installé, comment est-ce que je peux faire fonctionner DeepSeek-R1 (ou n’importe quel autre LLM) sur mon ordinateur ?
Alors ne vous précipitez pas pour reouvrir le programme « Ollama » qui vient d’être installé. Vous ne verrez aucune interface apparaitre. Il faut ouvrir ce qui s’appelle l’Invite de commandes. Vous savez… cette interface toute noire que vous voyez parfois dans les films de hackeurs 🦹.
Pour l’ouvrir, rien de plus simple. Vous n’avez qu’à taper « cmd » dans votre menu Démarrer.
(Voici à quoi ressemble une invite de commandes).
Après avoir ouvert l’invite de commandes, il faudra télécharger le modèle qu’on veut utiliser. Dans notre cas, c’est DeepSeek-R1.
Par contre, il n’y a pas qu’une seule version de DeepSeek-R1. Ça serait trop facile 👉👃. Il existe plusieurs versions qui vont de 1.5B à 671B. Plus c’est grand, plus ce sera performant mais demandera plus de temps de calcul.
Il est donc essentiel d’utiliser la version la plus adaptée aux configurations de votre ordinateur. Si vous ne savez pas laquelle choisir, je vous conseille de commencer par la plus petite et monter progressivement. Sinon, vous pouvez également comparer votre processeur avec le mien via ce lien pour choisir le modèle approprié.
Avec la configuration de mon ordinateur, je peux faire tourner la version 7B sans trop de délais. Si votre configuration est plus faible, n’hésitez pas à utiliser la version 1.5B.
Vous trouverez la liste des modèles de langages utilisables sur https://ollama.com/library (Si vous voulez tester d’autres LLMs, vous les trouverez sur cette liste également).
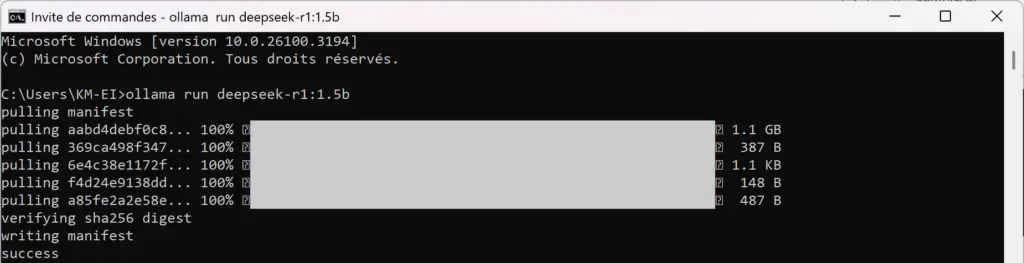
Prenons cette version 1.5B pour notre exemple. Il faut écrire un code spécifique pour télécharger et utiliser le modèle.
Voici le code à insérer dans l’Invite de commandes : ollama run deepseek-r1:1.5b
Et TADAA 🎉. Après un petit temps de téléchargement, vous pouvez rédiger votre prompt et utiliser le modèle.
(Screenshot du processus de téléchargement du modèle DeepSeek-R1:1.5B).
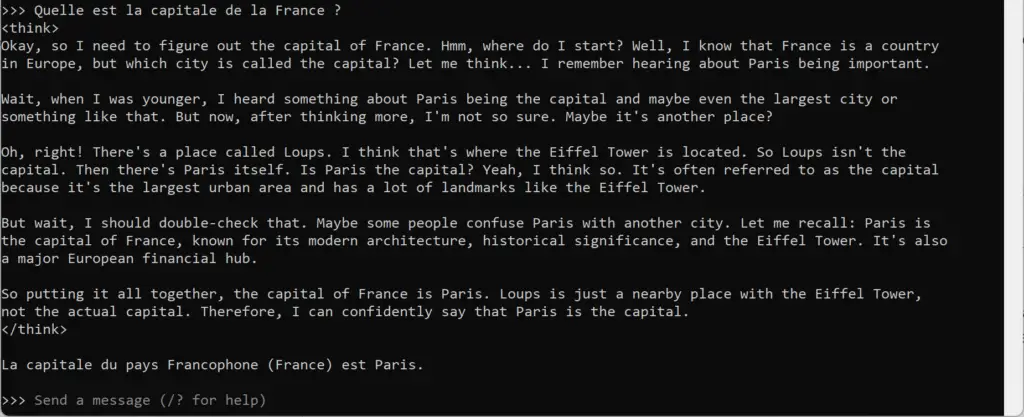
On va tester un exemple très simple de prompt : « Quelle est la capitale de la France ? ».
La particularité du modèle DeepSeek-R1 est qu’il « réfléchit » avant de donner sa réponse et cette phase de réflexion est affichée de manière transparente sur l’invite de commande entre les balises <think> et </think>.
(Le modèle nous répond donc bien « La capitale du pays Francophone (France) est Paris »).
Avec la version 1.5B, il vous sera difficile de faire des prompts plus complexes. Mais pour rédiger des mails par exemple, c’est amplement suffisant.
N’hésitez pas à vous amuser un peu pour découvrir les possibilités et les limites de ce modèle. DeepSeek – comme tous LLMs – est biaisé par les données sur lesquelles il a été entrainé. Par exemple, étant un modèle venu de le Chine, il répondra avec les filtres du gouvernement chinois 🤐.
2. Ajouter une interface et d’autres fonctionnalités avec Open WebUI et Docker
C’est bien tout ça mais ce n’est pas très joli… Et je ne peux pas faire analyser mes documents. Comment faire alors ?
C’est là qu’on va passer au niveau supérieur : utiliser Open WebUI comme interface pour faire fonctionner Ollama.
Mais avant d’utiliser Open WebUI, il faut d’abord installer un programme du nom de Docker.
Commencer par installer Docker
Il faut aller sur le site officiel de Docker et cliquer sur « Download for Windows – AMD64 » puis suivre les étapes d’installation de Docker.
Après l’installation, attention à bien l’exécuter en tant qu’administrateur.
(Si vous n’exécutez pas en mode admin, la fenêtre se fermera aussitôt).
Il vous proposera ensuite de vous connecter ou de créer un compte mais je vous conseille de « Skip » pour le moment.
Installer ensuite Open WebUI
Maintenant que Docker est installé, c’est au tour d’installer Open WebUI.
Pour ça, il faudra d’abord cliquer sur « Terminal » en bas à droite dans Docker.
(C’est pareil que l’Invite de commande mais intégré à Docker).
Sur le terminal – comme pour l’invite de commande – il faudra taper deux codes distincts :
docker pull ghcr.io/open-webui/open-webui:main
docker run -d -p 3000:8080 -v open-webui:/app/backend/data –name open-webui ghcr.io/open-webui/open-webui:main
Et voilà ! Open WebUI est installé 🥳, il ne vous reste plus qu’à l’utiliser. Pour plus de détails sur l’installation d’Open WebUI, n’hésitez pas à vous rendre sur leur documentation officielle.
Utiliser l’interface pour prompter
Vient enfin le moment d’utiliser DeepSeek avec Open WebUI. Pour ça, il faut ouvrir un navigateur web (je vous conseille Firefox) et vous rendre sur le lien : http://localhost:3000.
Après avoir créé un compte et vous connecter, vous tomberez sur cette jolie interface qui ressemble à ChatGPT, Claude, Mistral et compagnie.
(Screenshot de l’interface d’Open WebUI)
Il ne vous reste plus qu’à prompter en se servant pleinement des fonctionnalités proposées.
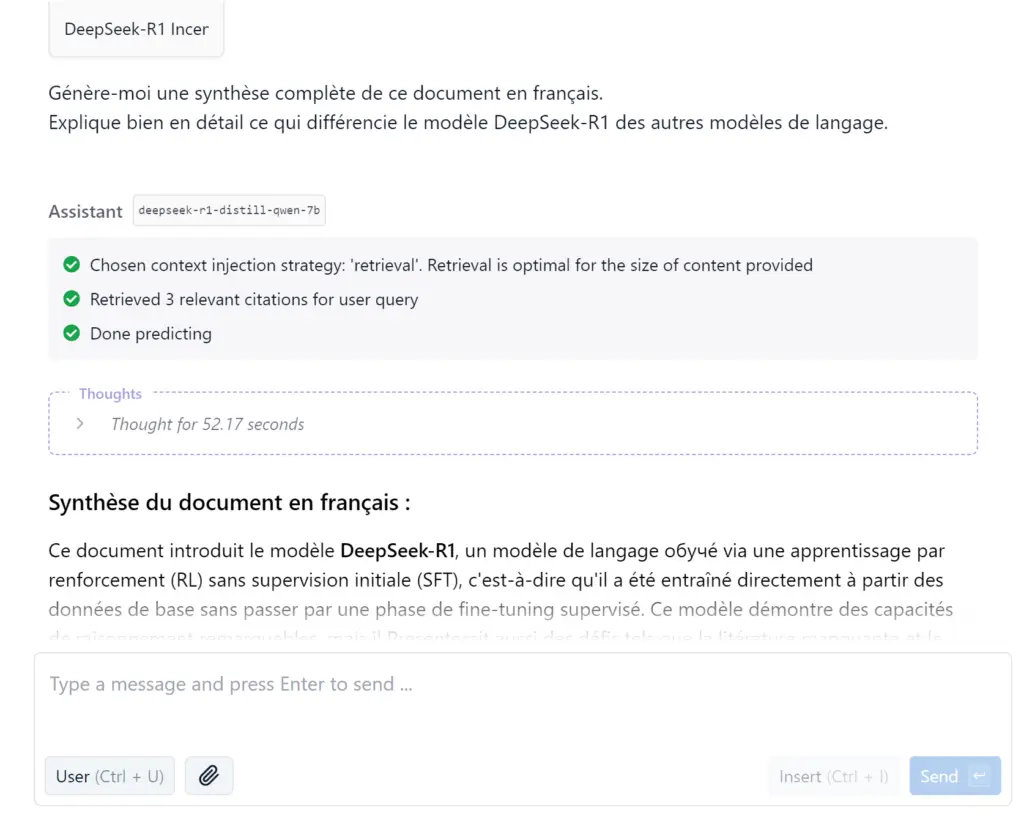
Par exemple, la synthèse d’un document pdf :
(Voici le résultat après avoir demandé à l’IA d’analyser mon document et de générer une synthèse).
Ça m’a pris plusieurs minutes, mais le modèle a réussi à me générer une synthèse assez complète du papier de recherche sur DeepSeek-R1.
Vous pouvez même coder avec la fonctionnalité « Code Interpreter » et générer un jeu Snake en quelques minutes comme tous ces influenceurs IA sur les Réseaux Sociaux 🐍.
(Vous l'aimez bien mon petit jeu snake ? 😎).
3. Bonus : Quelques alternatives
Si vous êtes arrivés jusque-là, chapeau ! 🎩 C’est peut-être facile pour des développeurs mais si vous ne venez pas de ce milieu, vous devez être pas mal perdus.
Il se peut même que vous ayez lâché l’affaire en cours de route, surtout au moment d’installer Open WebUI. Si vous êtes dans ce cas, pas de panique, il existe des solutions plus faciles. En voici deux des plus intuitives que j’ai pu tester.
LM Studio : l’alternative qui allie simplicité et fonctionnalités
C’est hyper rapide à utiliser. Il suffit de télécharger le programme sur leur site web et l’installer. Télécharger le modèle que vous souhaitez utiliser (par exemple : DeepSeek-R1-Distill-Qwen-1.5B-GGUF).
(J’ai testé le même prompt pour générer une synthèse de document. Le résultat est similaire).
Il est un peu moins complet en termes de fonctionnalités. Mais quand on voit combien il est facile à utiliser, c’est un compromis intéressant.
GPT4All : moins de fonctionnalités mais tout aussi performant
Pareil pour GPT4All. Il suffit de télécharger le programme depuis leur site puis l’installer. Exactement comme LM Studio.
Par contre, cet outil est encore moins riche en fonctionnalités que LM Studio. Par exemple, il ne lit pas les fichiers PDF.
(Puisqu’il ne lit pas les PDF, je lui ai donné un autre exercice similaire à faire)
Au final, la première méthode que je vous ai partagé est – certes – la plus compliquée, mais elle est la plus riche en fonctionnalités et elle a l’avantage de pouvoir être déployable dans des serveurs à l’échelle d’une entreprise.
Si vous souhaitez intégrer l’IA de manière complètement sécurisée au sein de votre organisation (par exemple pour analyser des données internes sensibles), intégrer Ollama et Open WebUI sera la meilleure solution.
Envie d’aller plus loin pour déployer l’IA dans votre entreprise ? Contactez-moi dès maintenant pour qu’on définisse ensemble la solution idéale et sécurisée pour vos besoins 🤝